La Text Encoding Initiative
Un poco de historia...
Hacia los años ochenta, diferentes tecnologías ya habían entrado a formar parte de ciertos campos de las Humanidades y Ciencias Sociales; recordemos por ejemplo que la lingüística de corpus ya había visto aparecer diferentes iniciativas de proyectos lexicográficos a gran escala, como el Index Thomisticus del padre Roberto Busa que contó con la colaboración de IBM.
El reto que se planteó entonces fue el de desarrollar, mantener y publicar un método de codificación de datos en un formato electrónico que fuera independiente tanto de hardware y sistemas operativos como de programas informáticos. Ante el crecimiento de sistemas diferentes de representación de materiales textuales, incluidos procesadores de texto, urgía la necesidad de ofrecer a la comunidad científica un método sólido para alargar la vida de sus datos y poder reutilizarlos en el futuro con objetivos diferentes. El hecho de que cada compañía ofreciera un programa y formatos propietarios entorpecía el trabajo académico y hacía difícil la planificación de proyectos a gran escala y de la larga duración.
Así pues, en 1987 tuvo lugar la primera reunión en el Vassar College (Poughkeepsie, NY), financiada por la Association for Computers in the Humanities y el National Endowment for the Humanities, con el fin de crear un sistema para la codificación de textos electrónicos. El texto que de ahí salió se puede consultar todavía en Design Principles for Text Encoding Guidelines.
En los años sucesivos, un comité, con la participación de más de 50 colaboradores, empezó la redacción de lo que acabaría siendo la primera propuesta de las Guías Directrices, conocida como TEI P1, publicada en junio de 1990. Se inició, posteriormente, una segunda fase con la creación de los hoy habituales "working groups" o grupos de trabajo por disciplina, con más de 100 colaboradores que, tras un trabajo de revisión y mejoras, publicaron una segunda propuesta. Pocos años después, en mayo de 1994, salieron las primeras Guías directrices oficiales (P3), para las cuales se había contado ya con más de 200 colaboradores.
Empezó entonces un enorme trabajo de difusión del modelo, a través de seminarios y talleres, pero sobre todo con muchos test y la retroalimentación de los colaboradores, que es lo que todavía hoy ayuda a identificar problemas, señalar necesidades concretas y proponer soluciones; para tal fin, TEI utiliza la plataforma GitHub donde se pueden solicitar nuevas funcionalidades TEI ("Feature Requests") o llamar la atención sobre errores existentes ("Bug").
En el año 2000 se creó, en fin, el Consorcio TEI que aspiraba a constituirse como una organización sin ánimo de lucro, permanente, académica y económicamente independiente. Una de las prioridades más urgentes que se planteó en ese momento fue la conversión de las Guías Directrices al lenguaje XML, pues las primeras se habían creado a partir del lenguaje SGML, un sistema más complejo, pesado y no tan ágil como XML. Así, solo dos años después, en 2002, apareció la P4, que por primera vez proponía un marco de trabajo basado ya en XML.
Finalmente, en noviembre de 2007, apareció la P5, que corresponde a la quinta propuesta todavía hoy en uso; periódicamente se realizan mejoras y se aumenta el número de su versión. El historial de actualizaciones puede encontrarse en su sitio web.
Estructura interna de la organización TEI
La Text Encoding Initiative es una organización internacional, fundada en el año 1987, encargada de desarrollar, mantener y publicar unas guías directrices para la codificación electrónica de textos en Humanidades y Ciencias Sociales.
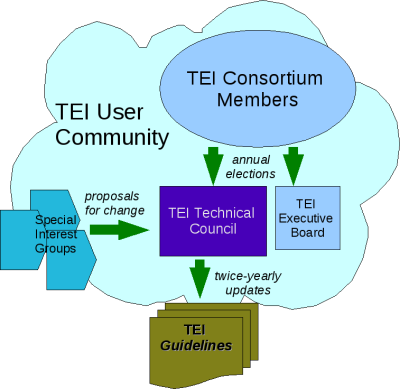
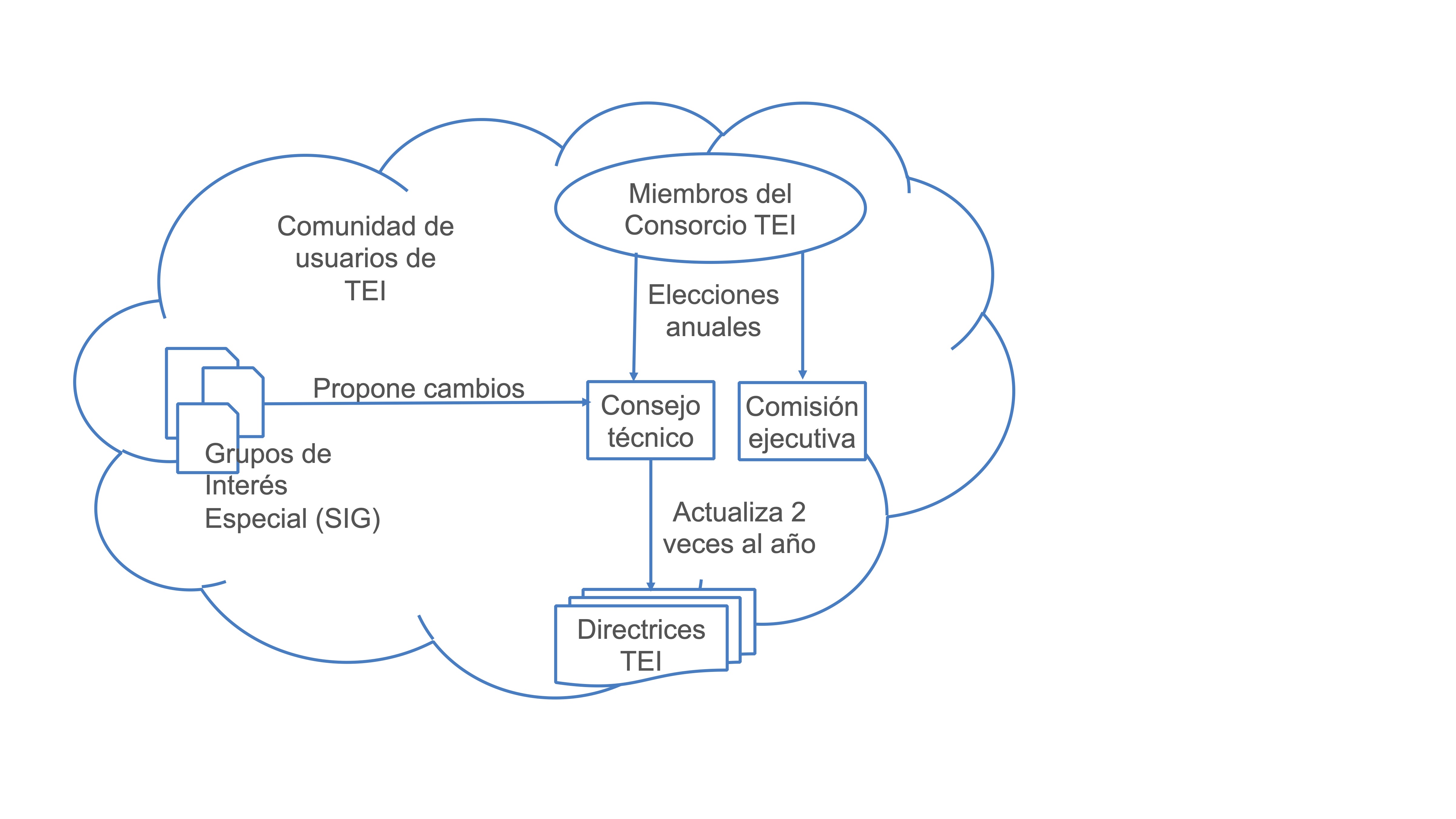
Desde el año 2000 su estructura organizativa se oficializó con la creación del Consorcio TEI que tiene una serie de objetivos:
- Desarrollo de las Guías Directrices TEI.
- Difusión y promoción de las Guías Directrices TEI.
- Formación y divulgación
- Promoción de una comunidad de investigación TEI.
Esta organización, sin ánimo de lucro, es autofinanciada por sus miembros y subscriptores que pueden ser instituciones (bibliotecas, universidades, proyectos académicos, unidades de investigación) y personas.
Tiene dos niveles de gestión:
- TEI Board of Directors, encargado de la gestión del Consorcio
- TEI Technical Council: 12 personas, encargadas de la elaboración y el desarrollo de las Guías Directrices
Además, TEI cuenta con otros dos niveles de participación y organización que consisten en grupos de trabajo especializados en una materia o disciplina concretas:
- TEI Workgroups: equipos de investigadores y profesionales que tratan cuestiones generales relativas al marcado TEI, como la gestión de la bibliografía o de informaciones biográficas, estructuras de rasgos, descripción de manuscritos, migraciones de sistemas de marcado o de versiones TEI diferentes, etc. Su trabajo se refleja de una manera concreta en las Guías Directrices.
- Special Interest Groups: grupos de personas con intereses específicos normalmente en contacto a través de las listas de discusión, como por ejemplo, el caso de la codificación de la correspondencia epistolar, el uso de TEI en bibliotecas o la codificación de música, el uso de ontologías o la creación de herramientas, entre otras cuestiones.
Todo ello, se engloba en la gran comunidad de usuarios conectada a través de la lista de correo electrónico y de espacios participativos como la Wiki.
Además de los talleres y seminarios que pueden tener lugar a lo largo del año, el Consorcio organiza desde el año 2001 una conferencia anual, las últimas de las cuales han tenido lugar en Lyon (2015), Vienna (2016), y Victoria (2017), Tokyo (2018) y Graz (2019).
En este esquema se refleja el engranaje de la comunidad TEI:
Cita
Allés Torrent, Susanna (2019). "Introducción a la Text Encoding Initiative". TTHub. Text Technologies Hub: Recursos sobre tecnologías del texto y edición digital. https://TTHub.io/aprende/introduccion-a-tei/
Copiar